SimCLR
본 게시글은 개인적인 공부를 위해서 작성된 글이니 비약적인 내용 또는 틀린 내용이 포함되어 있을 수 있습니다
SimCLR
Background
- Generative Learning
- Image as label (image 자체를 label로 활용함)
- AutoEncoder처럼, Decoder를 활용하여 학습을 진행함. Encoder 부분에서 학습되는 Representation을 위해서 Decoder가 필요하게 되므로 Computational cost가 큼.
- 더불어, Context Encoder도 마찬가지로 이미지의 일정한 부분을 잘라내고, 잘라낸 부분을 Encoder와 Decoder를 활용하여 다시 재구성하게 됨. 그리고 잘라낸 부분(GT) 은 알고 있기 때문에 같아지도록 학습을 진행할 수 있음.
- Proxy task learning
- self-made label by proxy task
- Decoder없이, Proxy task를 미리 설계하여, Unlabeled data에 Proxy label을 생성함.
- 이 때, Proxy task는 사용자가 직접 설계해줘야하는 부분이 있기 때문에 학습 과정에서 더 고차원적인 정보가 학습되는지 불명확함.
- Decoder 없이 SSL이 가능하다는 장점. Proxy Task 설정함에 있어 hueristics(인간의 개입)이 많이 필요함.
- Exampler(2014 NIPS) : 각각의 이미지 하나 하나에 레이블을 부여하고 classification task를 수행함. 예를 들면, ImageNet classification의 경우 1,000,000개의 레이블에 대해서 학습을 하게 됨. 그런데 각각의 이미지들은 Random한 Augmentation이 적용되어 같은 클래스로 취급함.
- Relative Patch Location(2015 ICCV) : 상대적인 위치를 학습하여 Representation을 학습함. 이미지를 9개로 짜른 뒤, 중앙에 있는 이미지과 주변의 8개 이미지 중 하나의 이미지 (총 2개의 이미지를) input으로 넣어 8개의 클래스 중 하나로 classification하게끔 학습함.
- Rotation (2018 ICLR) : 원본 이미지가 있을 때, 0도, 90도, 180도, 270도 돌린 이미지를 Convolution layer로 4개의 레이블로 classification하도록 학습 시킴. Rotation과 Relative Patch Location 모두 상대적인 위치를 고려한 학습이기 때문에 객체가 가진 깊은 특징까지 학습하기는 어려울 수 있음.
- Jigsaw Puzzle(2016 ECCV) 샘플 이미지를 9개의 patch로 나눈 뒤 이를 섞은 이미지에 레이블을 부여해서 classification task를 학습시킴.(9개니까 섞을 수 있는 경우의 수는 $9!$로 $362,880$ class.그러나 실제로는 이 중에서 $100$개의 class만을 뽑아 학습을 진행함). 이 역시도 깊은 representation을 학습하기 어려움.
- Contrastive Learning
- Learning by comparing images
- No Decoder
- No Proxy task
- with Contrastive Loss
- Premise : Augmentation은 Semantic한 정보를 바꾸지 않는다
- Positive Sample과 Negative Sample을 비교하며 학습
- Learning by comparing images
Contribution
-
Data Augmentation의 조합에 따른 성능을 실험
논문에서는 하나의
input에 대해서 두개의augmented view를 적용하는데, 어떤augmentation skill이 모델 성능 향상에 좋은 영향을 미치는지 실험을 진행하였음. -
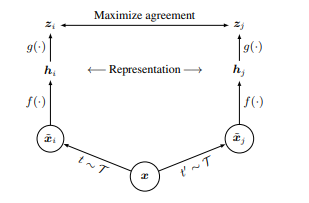
Projection Head 개념을 사용
$g$에 해당하는 부분으로 $f$(Resnet)등으로 추출된 Representation를 latent space로 projection 시켜줌.
- InfoNCE loss를 이용한 Contrastive learning을 SSL에 적용함.
논문에서는 InfoNCE Loss function을 NT-Xent라는 이름으로 소개(조금 다름…)하고 있는데, 아래와 같은 Loss function을 활용함.
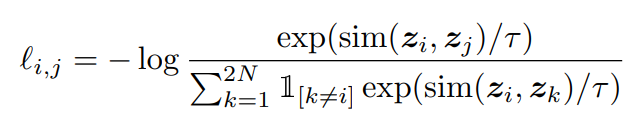
-
큰 배치 사이즈와 긴 학습
Epochs으로 성능을 향상시킬 수 있음.Contrastive learning의 핵심은 결국Postive pairs와Negative pairs를 비교하면서 학습을 하는 것이 가장 중요한데, 만일Down stream task에서 같은 이미지로 분류될 수 있는 이미지를Negative pairs로 보고 학습을 하게 되면, 적절치 않게 될 수 있음. 그러나 이러한 문제를 Large Batch size를 가져가면서 해결하였음.
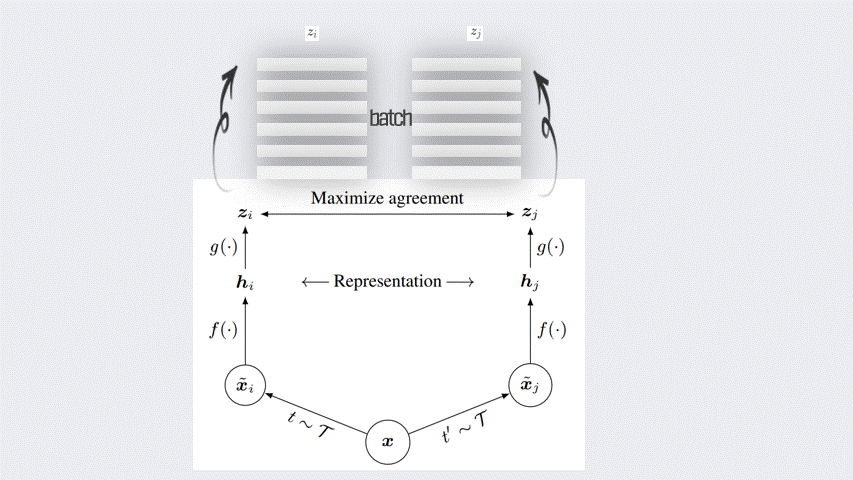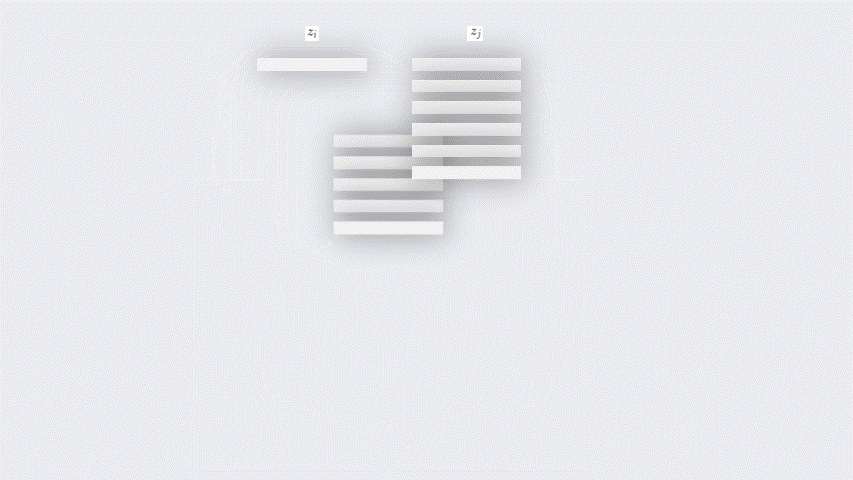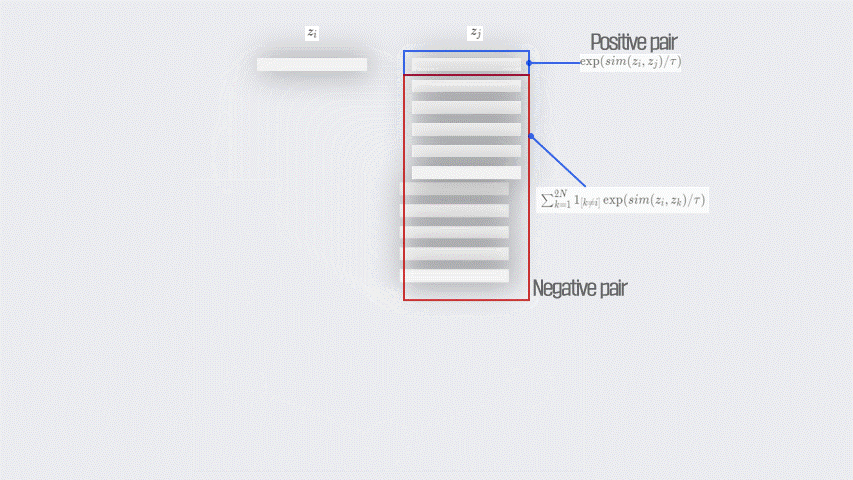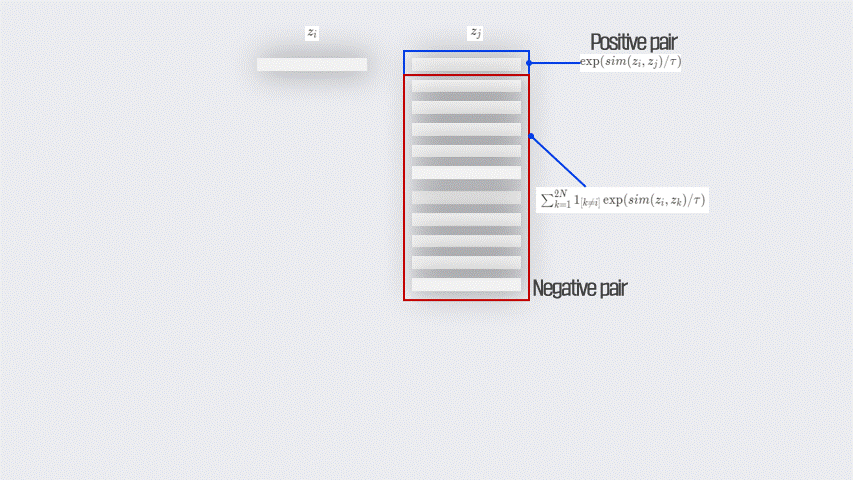
$\exp(sim(z_i,z_j)/\tau)$ : $z_i$와 $z_j$는 하나의 이미지로부터 augmentation이 적용된 뒤 $f$(backbone model) 를 거치고 projection head를 거쳐 나온 vector 값이다. 즉, $z_i$와 $z_j$는 postive pairs라고 볼 수 있는 것이다. $sim$의 경우 cosine similarity인데, 이를 활용하여 두 벡터간의 유사도(거리)를 구하게 된다. 따라서 분자에 해당하는 이 term은 Positive pairs에 대한 거리라고 생각해볼 수 있다.
$\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\exp(sim(z_i,z_k)/\tau)$ : 하나의 batch 내에서 $z_i$와 그외 나머지 모든 벡터 $z_k$간의 cosine similarity를 구한 뒤 모두 더한 것이다. 이때, 같은 augmented view로부터 나온 벡터 $z_j$ 또한 이 term에 포함된다. 그 이유는 당연하게도 더 안정된 Loss function을 취하기 위함이다. 물론, positive pair에 대한 계산도 포함되었지만, 이 부분은 어느정도 Negative pair에 대한 거리라고 볼 수 있다.
$l_{i,j} = -\log{\exp(sim(z_i,z_j)/\tau)\over\sum_{k=1}^{2N}\mathbb{1}_{[k\neq i]}\exp(sim(z_i,z_k)/\tau)}$: 다시 최종 식으로 돌아와서, $-\log$를 취해줬기 때문에 이 term에서 분자에 있는 Positive pair에 대한 거리는 커지고, 분모에 있는 Negative pair의 거리는 작아져야만 이 Loss function이 최소가 될 수 있다. 그리고 눈치챘을 수도 있지만, 이 함수는 통상적으로 Classification에서 쓰는 Negative Log Likelihood(NLL) 와 Logsoftmax의 합인 CrossEntropyLoss function과 동일하다.
Composition of data augmentation operations is crucial for learning good representations
what is the best augmentation for SimCLR?
SimCLR에 큰 틀이라고도 볼 수 있는 InfoNCE에 대해서 살펴보았다. 그런데 아직 어떤 augmentation을 적용해야 하는 의문점이 남아있다. 본 논문에서는 다양한 augmentation 조합을 적용하고, Linear Evaluation을 통해서 성과를 측정하였다. 더불어, 왜 특정한 augmentation이 더 좋은 representation을 학습하여 더 좋은 성능을 내었는지 설명한다.

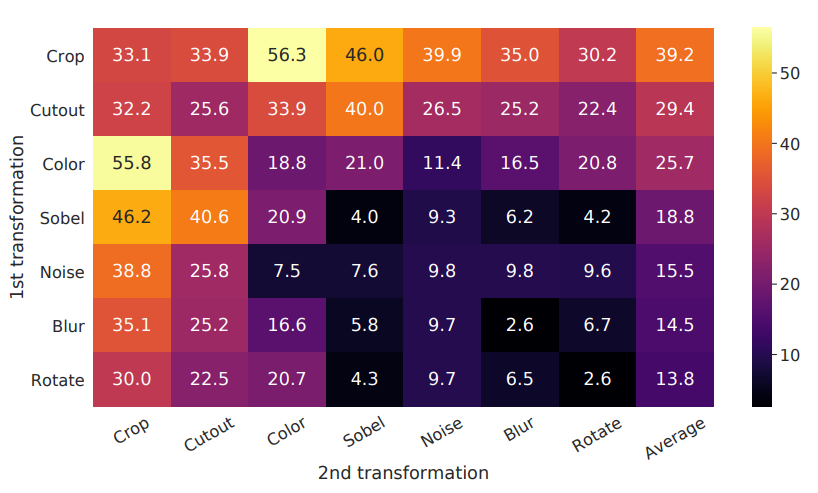
위의 시각화 자료를 보면, 동일한 augmentation을 적용한 경우 성능이 좋지 않다는 것을 알 수 있다. 그리고 특히, Crop과 Color distortion가 가장 월등한 성능을 보여주었다. 이 두가지 augmentation이 좋은 성능에 영향을 미치는 이유를 논문에서는 Color histogram을 통해 설명한다.
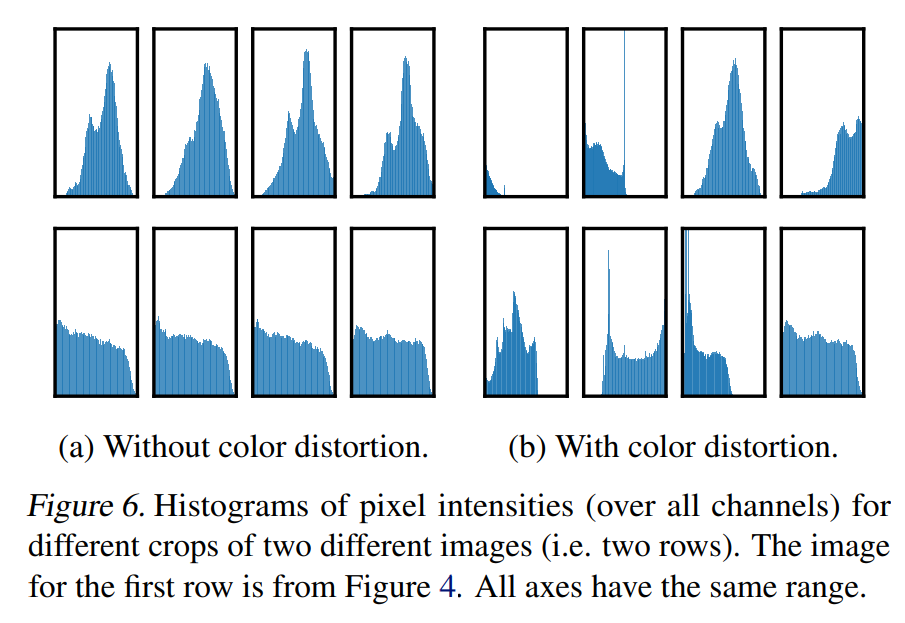
Color distortion을 적용하지 않을 경우, 위의 그림처럼 이미지의 색을 통해서 구분이 가능하도록 분포가 형성된다.즉, 이러한 경우 model이 학습과정에서 color를 통해 shorcut을 얻게 된다. 그러나 Color distortion을 적용하는 경우, 이러한 분포를 따르지 않기 때문에 color의 영향을 받지 않게 되어 더 좋은 representation을 학습할 수 있게 된다.
Contrastive learning needs stronger data augmentation than supervised learning
color distortion의 강도에 따른 성능 비교
앞서 SimCLR에서 color distortion을 사용할 경우, 성능이 다른 augmentation에 비해 좋다는 것을 알 수 있었다. 여기서 이 Color distortion이 representation 학습 및 linear evaluation 성능에 어떤 영향을 미치는지 supervised learning과 비교하여 실험을 진행하였다.
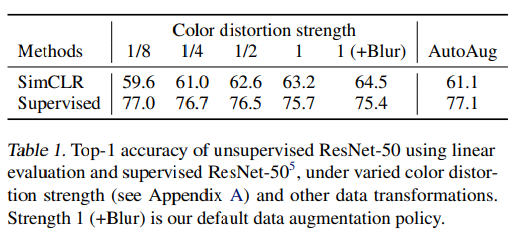
Color distortion의 strength을 변화시키면서 linear evaluation진행했을 때, SimCLR의 경우, supervised learning에 비해 더 augmentation이 성능에 영향을 많이 미치는 것으로 파악되었다.
Model Architectures
Unsupervised contrastive learning benefits (more) from bigger models
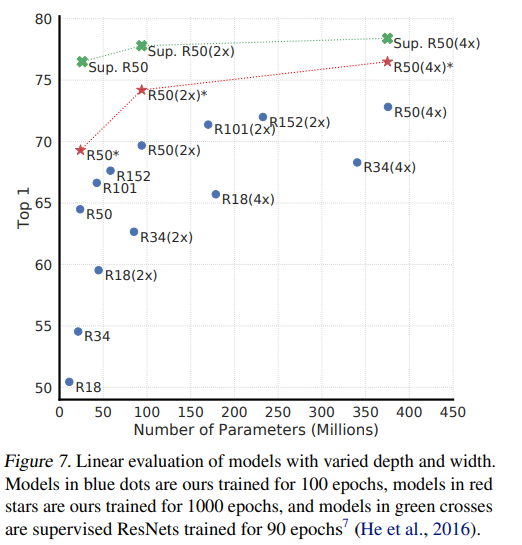
linear evalutation 성능의 경우 더 큰 모델을 사용하여 많은 parmeter를 학습할 때 성능 향상이 비교적(지도학습에 비해) 큰 것으로 나타났다.
A nonlinear projection head improves the representation quality of the layer before it
SimCLR는 $f$에 augmented input을 통과시켜 representation을 뽑아내는데, 이는 다시 아래의 architecture대로 latent space를 뽑아내기 위해 projection head $g$를 거치게 된다.
여기서 의문점은 어떤 projection head 를 사용해야 성능 향상에 도움이 될지 이다. 논문에서는 Activation Function이 없는 Linear Projection과 ReLU를 사용하는 Non-Linear Projection 그리고 FC layer 조차 사용하지 않고 Representation을 그대로 사용했을 경우를 비교하였다. 성능 비교에 대한 표는 다음과 같다.
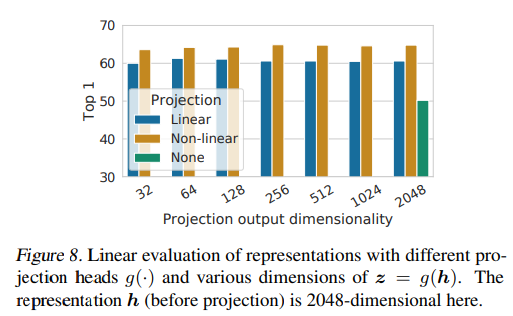
성능은 Non-linear projection을 사용했을 때, 가장 높게 나왔으며, Projection Head를 사용하지 않았을 경우 성능이 가장 낮게 나왔다. 또, 추가적으로 실험에서 주목할 점은 projection의 dimensionality에 따른 성능 변화가 없다는 점이다.
결론적으로, Non-linear projection을 사용하여 학습을 진행하고, 이로부터 나온 backbone weights를 사용하는 것이 더 좋은 성과를 보여준다고 이야기할 수 있다.
Which outputs are proper to downstream task
이제 Downstream task로 넘어와서 생각해볼 부분은 backbone weights를 가져와서 적용하는데, 그 전에 representation $h$ 뒤에 classifier(FC layer)를 붙혀 수행할 것인가 아니면 $z = g(h)$ 뒤에 classifier를 붙혀 수행할 것인가를 고민해보아야 한다. 여기서 contrastive learning이 어떻게 수행되는지 생각해보면 답은 정해져 있다. $z$는 한 이미지로부터 나온 augmented data들끼리는 가까워지도록 학습된다. 즉, $z$는 data transformation에 불변하도록 학습하게 된다. 이렇게 될 경우, downstream task에 적용될 수 있는 feature information를 어느정도 잃어버리게 되는 것이기 때문에 projection head를 거친 latent space $z$를 사용하는 것은 옳지 않다.
실제로 논문에서는 이와 관련해서 각각 representation $h$ 와 $z =g(h)$ 뒤에 FC layer를 추가하고, data transformation이 어떤 latent space에 잘 학습이 되었는지 classification task를 수행하여 확인하였다.
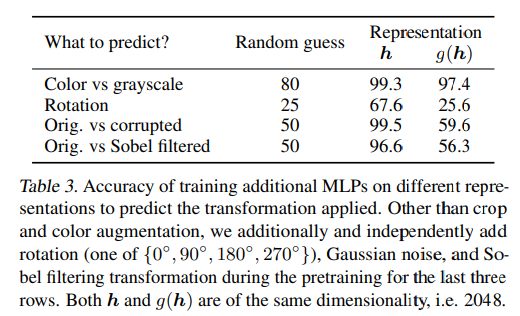
실제로도 representation$h$에 transformation이 적용된 information이 더 많이 포함된다는 것이 확인되었고, $z$의 경우 random guess와 유사한 성능을 보인 경우도 있는 것으로 확인되었다. 즉, $z$에는 data transformation이 적용된 information이 거의 없는 것으로 볼 수 있었다.
Loss functions and Batch size
Normalized cross entropy loss with adjustable temperature works better than alternatives
앞서 설명한대로 SimCLR에서는 Postivie pair와는 가깝도록, Negative pair와는 멀어지도록 InfoNCE라는 Loss function을 사용한다고 소개했었다. 그런데 실제로 SimCLR을 적용할 때는 NT-Xent를 사용하여 학습을 진행한다고 논문에서 소개한다. 이 함수는 cosine similarity term에 l2 normalization을 추가하여 matrix multiplication만 남게 만든 것을 빼면 동일하다.

Hard Negative Mining
여기서
Hard Negative란 이란 기준이 되는anchor$u$로부터Positive pair$u^+$ 까지의 거리보다Negative pair$u_-$까지의 거리의 거리가 더 가까운 경우를 이야기하는데 (즉, 데이터가 잘 분리되어 있지 못한 상황 ! ) 앞서 이야기한대로NT-Xent는Negative pair에 상대적으로 큰 가중치를 부여하도록 하기 때문에Hard Negative에 대해서도 잘 작동하는 모델이 되도록 한다.
이와 관련해서 각각
l2 normalization을 적용하지 않은loss function과l2 normalization을 적용한loss function그리고NT-Xent를linear evaluation을 통해 비교하였는데,Hard Negative Mining에 효과적인NT-Xent가 가장 좋은 성능을 보여주었다.더불어,
l2 normalization의 유무에 따른 성능도 측정을 하였는데,l2 normalization이 성능 향상에 도움이 되는 것으로 보여졌다.
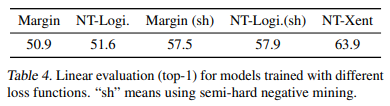
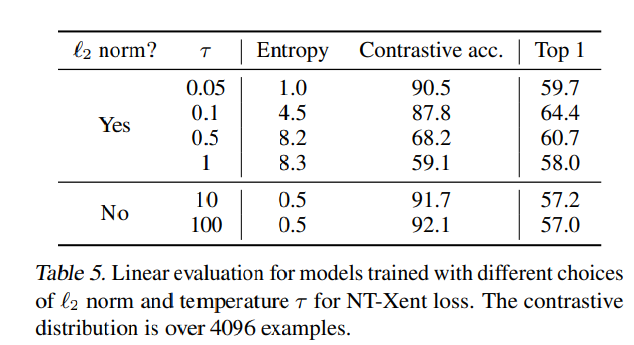
$\tau$의 유무 그리고 l2 normalization의 유무가 실험을 통해서 있을 때, 더 좋은 성능을 보여준다.
Contrastive learning benefits (more) from larger batch sizes and longer training
SimCLR는 Negative pair를 설정할 때, 큰 Batch size를 설정하여 Negative pair내에 positive pair와 비슷한 도메인의 데이터가 어느정도 있더라도 이에 대한 영향력을 상쇄시킬 수 있도록 하였다. 논문에서는 batch size를 크게 설정할 수록 더 좋은 성능을 보여줌과 동시에 training epochs를 늘릴 수록 더 좋은 representation 학습을 하게 됨을 보여주었다.
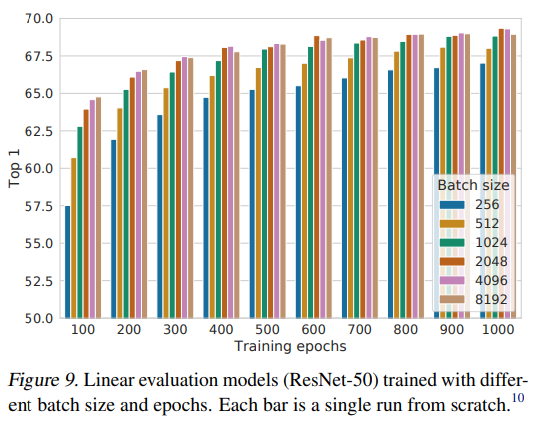
댓글남기기