BYOL
본 게시글은 개인적인 공부를 위해서 작성된 글이니 비약적인 내용 또는 틀린 내용이 포함되어 있을 수 있습니다
BYOL
contrastive learning은 No decoder, No proxy task, InfoNCE loss라는 특징을 지니고 있다. Contrastive learning 답게 Positive Pairs와 Negative Pairs를 잡아줘야 하는 한계가 있는데, BYOL(비욜?)은 이러한 한계를 극복하고자 제시된 모델이다.
(MoCo, SimCLR 두 모델 역시 Negative pairs를 어떻게 설정하느냐의 차이일 뿐 결국 Negative pairs에 민감하게 반응하는 모델이다.)
BYOL은 가장 큰 특징을 몇 가지 열거해 보면,
- Only Positive Pairs
- Prevent collapsing by distillation (asymmetric) : Loss를 augmented view가 적용된 input을 switching하여 계산
- Robust to batch size
- Robust to augmentation settings
Collapsing Problem
Postive Pairs만을 이용해서 학습을 진행하게 되면, 같은 이미지로부터 나온 두 embeddings만을 가깝게 만드는 과정이 진행됨.
이 프로세스가 가지는 문제점은 모델 입장에서는 항상 똑같은 두 상수만 출력하도록 학습하기만 하면 두 embeddings 간의 거리는 0이 되어(같은 값이므로) shortcut을 이용한 학습이 가능해짐. 이렇게 되면 모델이 collapsed되게 됨.
그래서 BYOL처럼 postive pairs만으로 학습하는 method들은 이러한 한계(Collapsing Problem)가 있기 때문에 이를 예방하는 것에 방점을 두고 있다.
Method
Online Network & Target Network
두 개의 augmented view 가 적용된 Input은 서로 다른 네트워크 $f_{\theta}$ , $f_{\xi}$로 들어가게 되는데, 각각 online network, target network로 들어 가게 된다. 그리고 각각은 MLP layer인 projection head를 거쳐 $z$ 을 구하게 된다. 그런데 이 때, oneline network의 $z_{\theta}$는 다시 prediction head를 거치고, 이 때의 아웃풋으로 network Projection의 output을 예측하는 방식으로 학습이 진행된다. 그리고 gradient의 경우 online network의 방향으로만 흘러가게 된다.
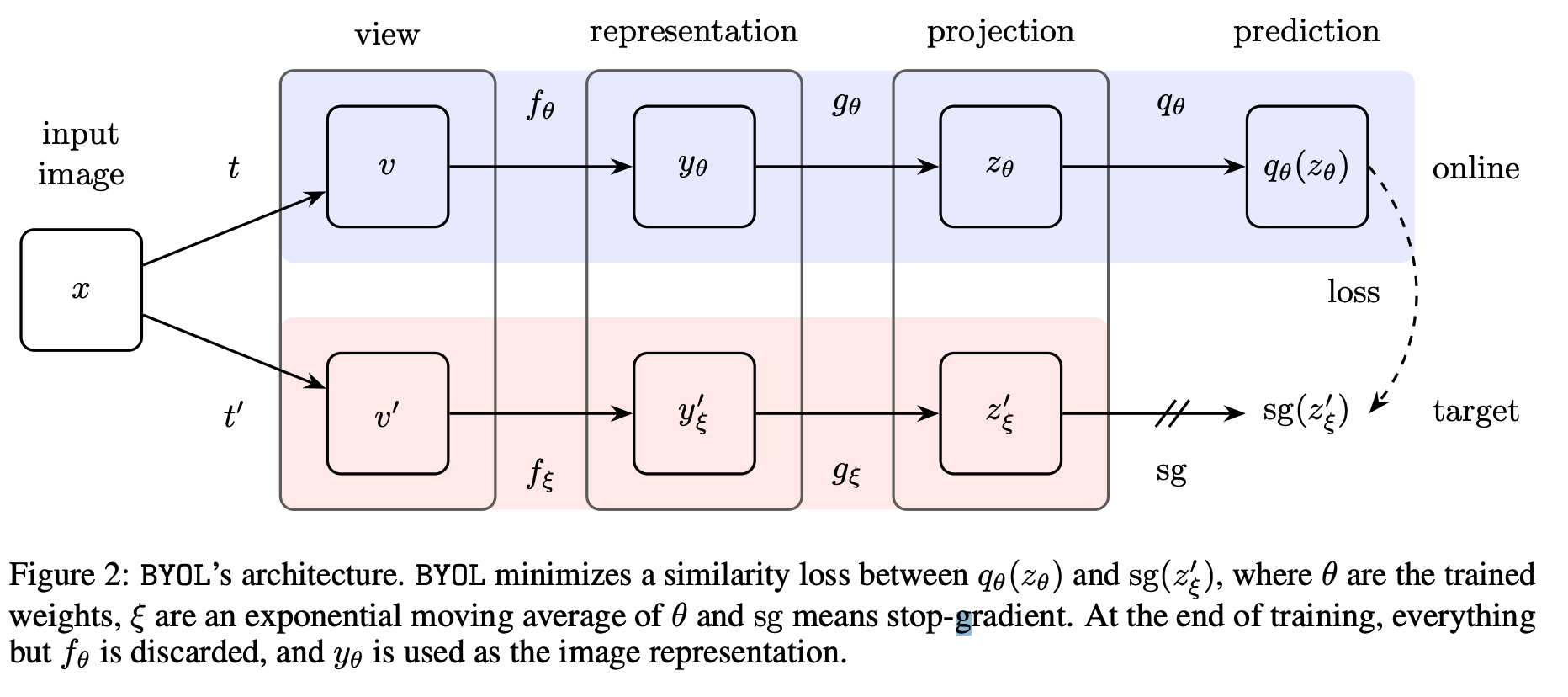
정리하자면, oneline network의 최종 Prediction head의 output으로 target network의 projection head의 output을 예측하는 문제이다. 이 때, online network는 target network에 어떤 augmented view가 적용되지 모르고, 그로 인해 prediction head는 target network를 거친 projection space의 평균을 예측하도록 학습이 진행된다. 따라서 예측을 하더라도 어떤 sample을 완벽하게 예측하는 것이 아닌 전반적인 특성을 예측하므로 collapse한 현상이 일어나지 않게 된다.( 이 부분은 내가 맞게 설명한 것인지 모르겠다.)
L2 Loss (Not using InfoNCE)
BYOL의 경우 negative pairs에 대한 부분을 고려하지 않아도 되므로 (InfoNCE에서 분모에 해당하는 부분), negative cosine similarity를 사용하게 된다. 아래의 수식은 L2 loss를 negative cosince similarity로 바꾼 형태가 되겠다.
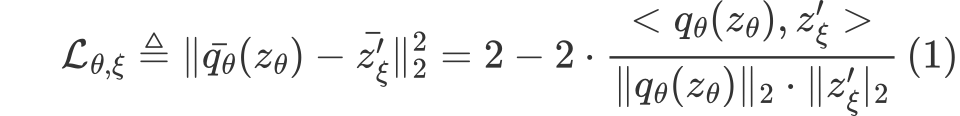 그리고 더불어 symmetric loss를 사용했다고 하는데, 그 이유는 loss를 계산한 뒤, target network의 view $v’$를 oneline network로, oneline network의 view $v$로 넘겨주고 학습을 진행하기 때문이다.
그리고 더불어 symmetric loss를 사용했다고 하는데, 그 이유는 loss를 계산한 뒤, target network의 view $v’$를 oneline network로, oneline network의 view $v$로 넘겨주고 학습을 진행하기 때문이다.
Momentum update & stop gradient
MoCo와 유사하게 BYOL에서도 Momentum updaterk 적용이 된다. 다시 말해, target network의 경우 backpropogation이 이루어지는 대신 oneline network의 weights를 활용해 조금씩 update가 진행된다.
Implementation details
- Image Augmentation
- SimCLR와 동일하게 적용
- Architecture
- Oneline Network :
- Encoder : ResNet50 + GAP(2048)
- Projector : FC layer 4096 + BN + ReLU $\rightarrow$ FC layer 256
- Predictor : FC layer 256
- Target Network :
- Encoder : ResNet50 + GAP(2048)
- Projector : FC layer 4096 + BN + ReLU $\rightarrow$ FC layer 256
- predictor : None !
- Oneline Network :
- Optimization
- LARS, cosine decay learning rate schedule, 1000 epochs
- Learning Rate = 0.2 * Batch_size / 256
- $\tau$ = 0.996 ~ 1
- Batch_size : 4096
Experiment
self-supervised learning 을 활용하여 다양한 실험들을 논문에서 진행하고 있는데 열거하면,
- Linear Evaluation
- Semi-supervised learning
- Transfer learning
- Robustness to batch size & augmentation
이 있다.
Linear evaluation

ResNet50 architecture에서 SimCLR와 MoCo v2처럼 negative pairs를 잡는 방식으로 학습하지 않았는데도 성과 측면에서 더욱 고무적인 결과를 보였다. 또 다른 architecture에서 또한 더 좋은 성능을 보이고 있다.
Semi-supervised learning
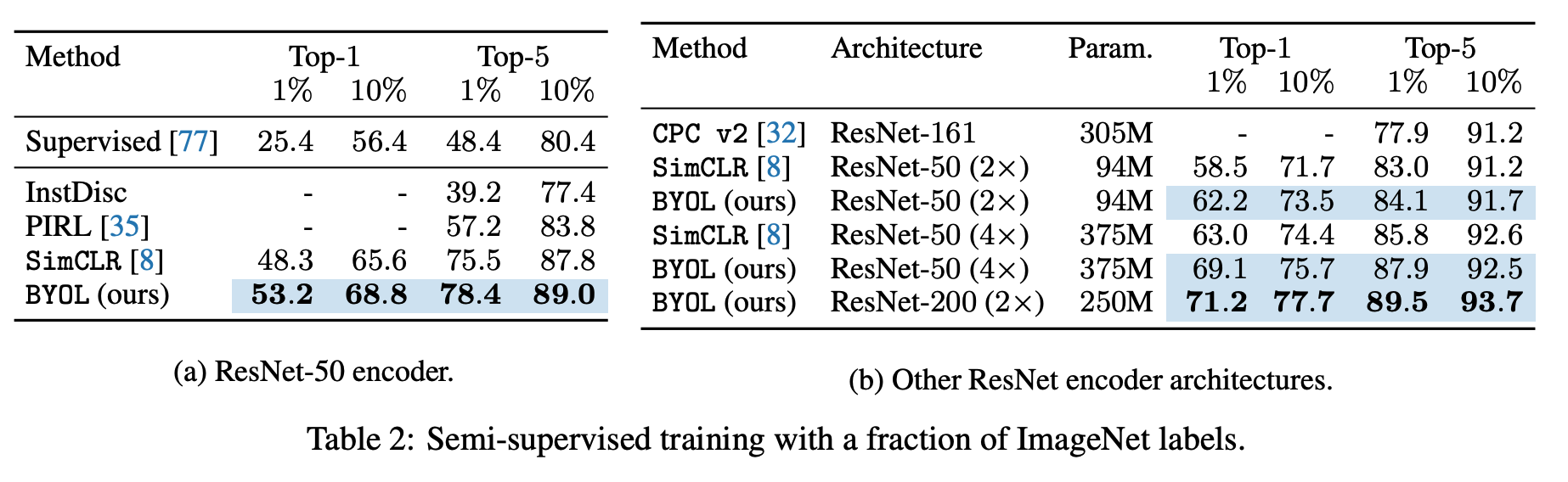
여기서도 마찬가지로 SOTA 의 성능을 보이고 있다.
Transfer learning
먼저 ImageNet 데이터 셋으로 모델을 self-supervised learning으로 학습시킨 다음 Transfer learning을 한 결과 역시 더 좋은 성과를 보이고 있다.
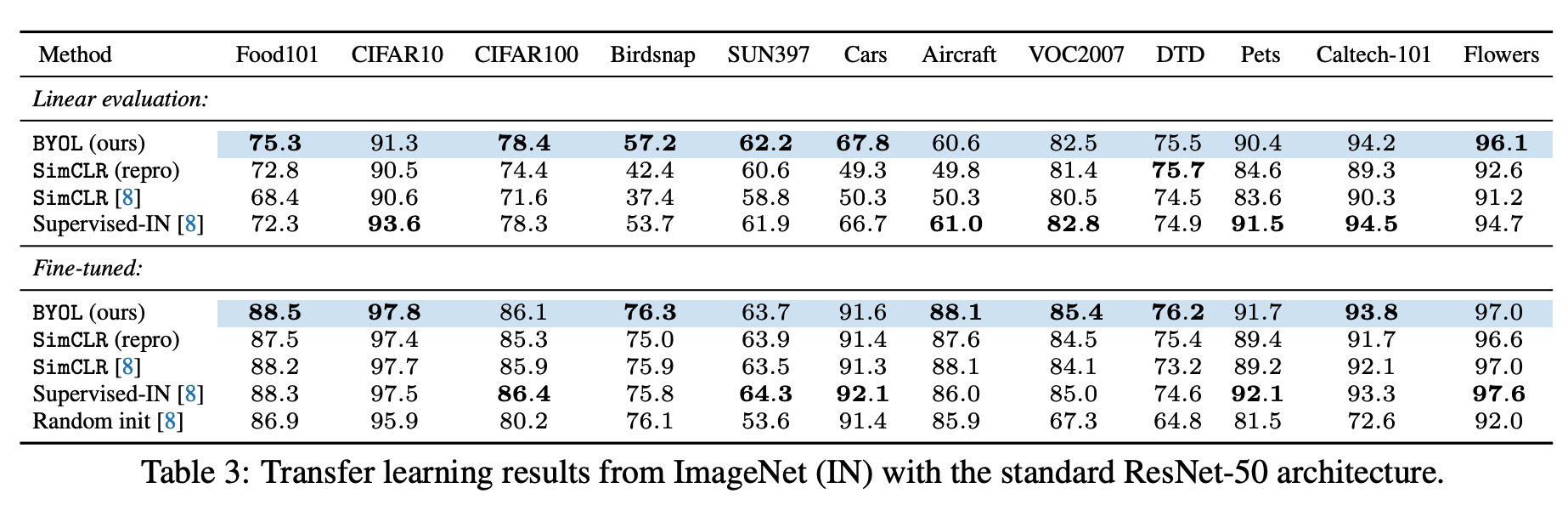
Linear Evaluation 에서 FC layer만 학습하도록 했을 때도 다른 모델에 비해서 대체로(여러 데이터셋에 대해) supervised learning보다 좋은 성능을 보였다.
또, 모델 전체를 fine-tuning한 모델들의 경우에 대해서 supervised learning을 앞지르는 성능을 보였다.
Robustness to batch size & augmentation
실험 결과를 살펴보면, SimCLR에 비해 Batch Sizefmㄹ 줄여도 성능의 감소폭이 현저히 낮고, augmentation 역시 제거하였을 때, 감소하는 성능의 폭이 낮은 것으로 나타났다.
Conclusion
- Positive pairs만으로 self-supervised learning 을 선보인 첫번째 논문
- Momentum update와 Oneline Network와 Target Network를 사용하는 distillation based approach 를 활용해서 collapse한 문제를 해결
- 높은 성능과 함께, batch size, augmentation setting에 robust함.
댓글남기기